LLM Reference
Every week brings new models, prices, and benchmarks, but LLM Reference helps you cut through the noise to pick the right LLM for what you are.
Visit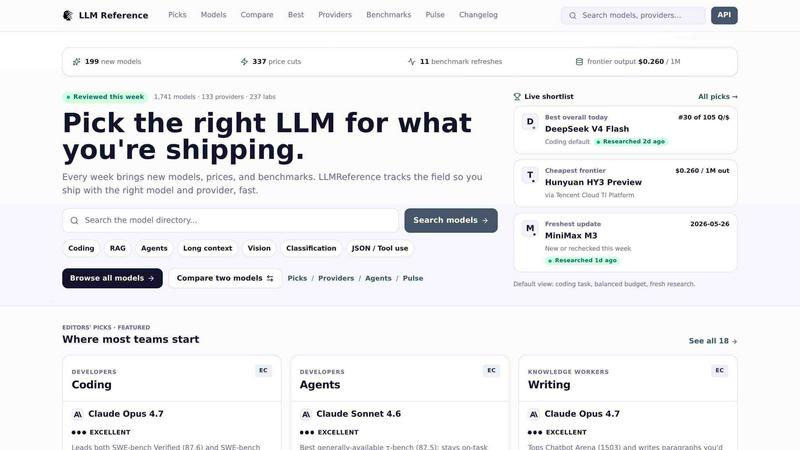
About LLM Reference
Every week, the landscape of large language models shifts. A new frontier model appears, a provider slashes prices on their API, or a benchmark result reshuffles the leaderboard. For engineers and technology leaders tasked with shipping products that rely on these models, this constant change creates a painful problem: how do you choose the right model and provider with confidence, without spending hours hunting through scattered sources, blog posts, and social media feeds? LLM Reference is the answer. It is a decision-support directory built to solve this exact challenge. At its core, LLM Reference tracks over 1,800 language models from more than 140 providers and 247 research labs. The data is refreshed weekly, capturing new releases, verified price changes, and benchmark updates as they happen. The product is designed for fast triage. You land on the site, and within moments, you can identify the best model for your specific task, find the most cost-effective provider for frontier output, and get back to building. Whether you are constructing a coding assistant, an agentic workflow, a writing tool, or a research pipeline, LLM Reference gives you a single, trustworthy place to compare models side-by-side. It features curated editors' picks for specific tasks like coding, agents, writing, research, image generation, and video creation. A Pulse feed highlights what changed this week, including new models, price cuts, and benchmark refreshes, keeping you informed without the noise. Built by the Data Advantage project and updated daily, LLM Reference is an essential resource for anyone who needs to stay current with the exploding LLM ecosystem and ship with confidence.
Features of LLM Reference
Comprehensive Model Directory
LLM Reference maintains a searchable directory of over 1,800 language models from more than 140 providers and 247 research labs. You can search by model name, provider, or task, or browse all models to see the full landscape. Each entry includes key details like pricing, context length, and benchmark scores, giving you a complete picture in one place.
Curated Editors' Picks
The site features expert-curated recommendations for specific tasks, such as coding, agents, writing, research, image generation, and video creation. These picks are based on real-world performance, benchmark results, and practical experience. For example, the coding default is Claude Fable 5, while the best overall video quality is Veo 3.1. Each pick includes a rationale and links to eligible alternatives.
Live Pulse Feed
The Pulse feed is your weekly snapshot of what changed in the model market. It tracks new model releases, verified provider price cuts, and benchmark refreshes. You can see at a glance that there are 177 new models, 53 price cuts, and 368 benchmark refreshes this week. This feature keeps you informed without requiring you to follow dozens of separate sources.
Side-by-Side Model Comparison
You can directly compare two models to see their strengths and weaknesses across key dimensions. The site also provides a Cheat Sheet section with the most-asked comparisons, such as Claude Fable 5 versus GPT-5.5 or Claude Opus 4.8 versus Claude Opus 4.7. This makes it easy to understand the trade-offs between leading models.
Use Cases of LLM Reference
Selecting a Model for a Coding Assistant
An engineering team building an AI-powered coding assistant needs a model that excels at code generation, debugging, and understanding complex programming contexts. Using LLM Reference, they can filter by the "Coding" task, review the editors' picks like Claude Fable 5, and compare its SWE-bench scores against alternatives like GPT-5.5 or DeepSeek V4 Flash. They can also check pricing per million tokens to find the most cost-effective option for their expected usage volume.
Choosing a Provider for an Agentic Workflow
A developer creating an autonomous agent that performs multi-step tasks requires a model with strong tool-use capabilities and long context handling. LLM Reference allows them to browse the "Agents" board, see that Claude Sonnet 4.6 is the top pick with a tau-bench score of 87.5, and compare it against other eligible models. They can then check which providers offer the best pricing for that model's output, ensuring their agent stays within budget.
Finding the Best Model for Image Generation
A creative agency needs to generate brand-consistent, photorealistic images for a client campaign. They can use LLM Reference to navigate to the "Image" board, see that FLUX.2 Dev is the current photoreal leader, and read the rationale explaining why it excels at text rendering and hands. They can also explore alternatives like DALL-E 3 or Midjourney v6+ and compare their capabilities side-by-side before making a final decision.
Evaluating Cost-Effective Frontier Models
A startup with limited budget wants to use a frontier-level model for a research pipeline but needs to minimize costs. LLM Reference provides a "Cheapest frontier" pick, currently showing Hunyuan HY3 Preview via Tencent Cloud TI Platform at $0.260 per million output tokens. The user can then explore the "Frontier pricing" signal to see verified price cuts and compare rates across different providers for the same or similar models.
Frequently Asked Questions
How often is the data in LLM Reference updated?
The data is refreshed weekly to include new model releases, verified price changes, and benchmark updates. The site is built by the Data Advantage project and updated daily, ensuring that the information you see is as current as possible. The Pulse feed specifically highlights what changed in the most recent week.
Is LLM Reference free to use?
There is no pricing information provided in the context. The site appears to be a free resource for comparing models and providers, making it accessible to engineers and technology leaders who need decision support without a subscription cost.
How are the editors' picks determined?
Editors' picks are curated based on a combination of benchmark performance, real-world task suitability, and expert analysis. Each pick includes a rationale, such as "Best generally-available tau-bench (87.5)" for Claude Sonnet 4.6 in agents, or "Tops Chatbot Arena (1503)" for Claude Opus 4.7 in writing. The picks are regularly reviewed and updated as new models and benchmarks emerge.
Can I compare more than two models at once?
The primary comparison tool allows you to compare two models side-by-side. However, you can also browse the "Best of" boards and editors' picks to see multiple models ranked for a specific task. The Cheat Sheet section provides direct comparisons for the most frequently asked pairings, helping you quickly understand the differences between leading models.
Pricing of LLM Reference
There is no pricing information available for LLM Reference itself. The product appears to be a free directory and decision-support tool. The pricing information displayed on the site refers to the API costs of the third-party language model providers, which LLM Reference tracks and verifies.
Similar to LLM Reference

GeoRank
Planning a relocation or long-term stay abroad? Compare places on sunshine, cost, tax, visa access for your passport, then ask AI about your short
SLABCALC
SlabCalc is a free suite of 34 concrete calculators plus AI tools for crack diagnosis and quote analysis. Instant answers for your concrete project.
Adviserry
Automatically get personalized actions from your YT, podcast, and email subscriptions.

FeatureShark
Stop wasting dev spend on the wrong features. Turn raw user feedback into clear, revenue-driving product decisions with AI agents.
PrettyScale
Free AI tools to analyze your face attractiveness, find your celebrity look-alike, and calculate your body shape — instant results, no signup.
AuditBadger
SOC 2 and ISO 27001 turned into a clear to-do list. AI prepares the first drafts, you approve every call, and the founders actually answer.
