Agenta
Agenta unifies your team's journey from scattered prompts to reliable, collaborative LLM applications.
Visit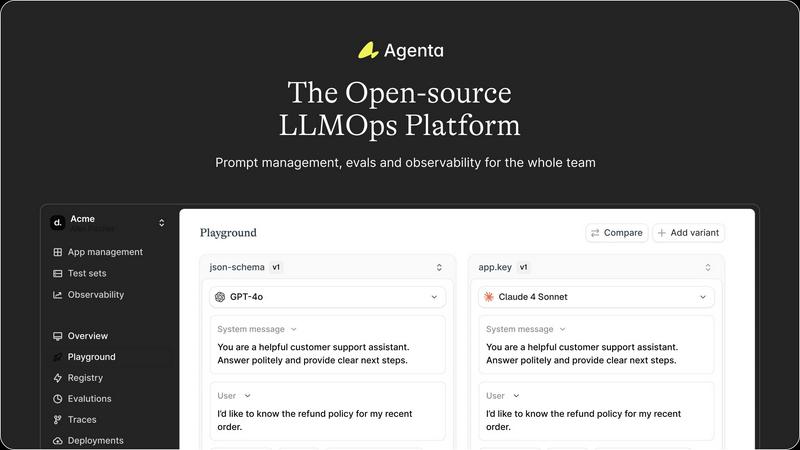
About Agenta
The journey of building with large language models is often a tale of chaos. Prompts are scattered across emails and Slack threads, experiments are launched on gut feeling, and debugging a failure in production feels like searching for a needle in a haystack. This is the unpredictable reality most AI teams face, where brilliant ideas get lost in siloed workflows and unreliable deployments. Agenta emerges as the guiding path through this wilderness. It is an open-source LLMOps platform designed to be the single source of truth for teams building reliable LLM applications. Agenta transforms the fragmented process into a structured, collaborative journey. It brings developers, product managers, and domain experts together into one unified workflow, allowing them to experiment with prompts, run systematic evaluations, and observe application behavior in production—all from a centralized platform. By replacing guesswork with evidence and silos with collaboration, Agenta empowers teams to iterate quickly, validate every change, and ship AI products you can truly trust.
Features of Agenta
Unified Playground & Experimentation
Agenta provides a central, model-agnostic playground where your team can safely experiment with different prompts, parameters, and models from any provider side-by-side. This eliminates the need for scattered scripts and documents. Every iteration is automatically versioned, creating a complete history of your experiments so you can track what changed, why, and its impact. Found a problematic output in production? You can instantly save it as a test case and begin debugging right in the same interface.
Systematic Evaluation Framework
Move beyond "vibe testing" with Agenta's robust evaluation system. It allows you to create a systematic process to run experiments, track results, and validate every change before deployment. The platform supports any evaluator you need—LLM-as-a-judge, custom code, or built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into the evaluation workflow.
Production Observability & Debugging
When your LLM app is live, Agenta gives you clear visibility. It traces every user request, allowing you to pinpoint the exact step where failures occur. You and your team can annotate these traces to discuss issues or gather user feedback directly. With a single click, any problematic trace can be turned into a test case, closing the feedback loop. Live, online evaluations monitor performance continuously to detect regressions as they happen.
Collaborative Workflow for Whole Teams
Agenta breaks down silos by providing tools for every team member. It offers a safe, no-code UI for domain experts to edit and experiment with prompts. Product managers and experts can run evaluations and compare experiments directly from the UI, while developers work via a full-featured API. This parity between UI and API creates one central hub where everyone collaborates on experiments, versions, and debugging with real data.
Use Cases of Agenta
Streamlining Enterprise Chatbot Development
A financial services company is building a customer support chatbot. Their domain experts, compliance officers, and developers need to collaborate tightly. Using Agenta, they centralize prompt versions, run evaluations against regulatory compliance checklists and customer intent accuracy, and observe live interactions to quickly debug hallucinations or incorrect advice, ensuring a reliable and compliant final product.
Building and Tuning Complex AI Agents
A team is developing a multi-step research agent that searches the web, summarizes findings, and generates reports. Debugging is a nightmare when only the final output is wrong. With Agenta, they evaluate each intermediate step in the agent's reasoning chain, identify which tool call failed, and use the unified playground to iteratively fix the prompt for that specific step, dramatically improving the agent's reliability.
Managing Rapid Product Iteration with LLMs
A product team at a SaaS company uses LLMs to generate personalized email content. Marketing wants to test new tones, while engineers worry about stability. Agenta allows them to A/B test different prompt variations systematically, gather quantitative scores on engagement metrics and qualitative feedback from the sales team, and confidently deploy the winning variant with full version control and rollback capability.
Academic Research and Model Benchmarking
A research lab is comparing the performance of various open-source and proprietary LLMs on a new benchmark task. They use Agenta's model-agnostic playground to run the same prompt templates across all models, automate scoring using custom evaluation scripts, and maintain a rigorous, reproducible record of all experiments and results in one platform, streamlining their publication process.
Frequently Asked Questions
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can dive into the codebase on GitHub, self-host it on your own infrastructure, and contribute to its development. This ensures transparency, avoids vendor lock-in, and allows for deep customization to fit your specific LLMOps workflow and security requirements.
How does Agenta handle data privacy and security?
As an open-source platform, Agenta gives you full control over your data. You can deploy it within your private cloud or on-premise environment, ensuring that all prompts, evaluation data, and production traces never leave your network. This is crucial for enterprises in regulated industries like healthcare, finance, or legal services.
Can I use Agenta with my existing LLM framework?
Absolutely. Agenta is designed to be framework-agnostic. It seamlessly integrates with popular frameworks like LangChain and LlamaIndex, and it works with any model provider (OpenAI, Anthropic, Cohere, open-source models via Ollama, etc.). You can bring your existing applications and connect them to Agenta for the management, evaluation, and observability features.
Who on my team should use Agenta?
Agenta is built for the entire LLM application team. Developers use the API and SDK for integration, product managers and domain experts use the no-code UI to run evaluations and tweak prompts, and AI leads use the platform to oversee the entire experimentation lifecycle and production health. It bridges the gap between technical and non-technical stakeholders.
Explore more in this category:
Similar to Agenta
HypeShare
Secure file transfer platform for sending large files fast — no signup required, end-to-end encryption, up to 10GB free.
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.
Headless Domains
Headless Domains empowers AI agents with secure, verifiable identities, enabling trust and seamless interactions across digital platforms.
LoadTester
LoadTester lets you run and monitor load tests from your browser to catch performance issues before they reach production.
ProcessSpy
ProcessSpy empowers you to masterfully monitor and analyze macOS processes with advanced features and seamless integration for a pro-level experience.