Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right product.
Agenta unifies your team's journey from scattered prompts to reliable, collaborative LLM applications.
Last updated: March 1, 2026
Stop guessing which AI model fits your task and let OpenMark benchmark over 100 models for you in minutes.
Last updated: March 26, 2026
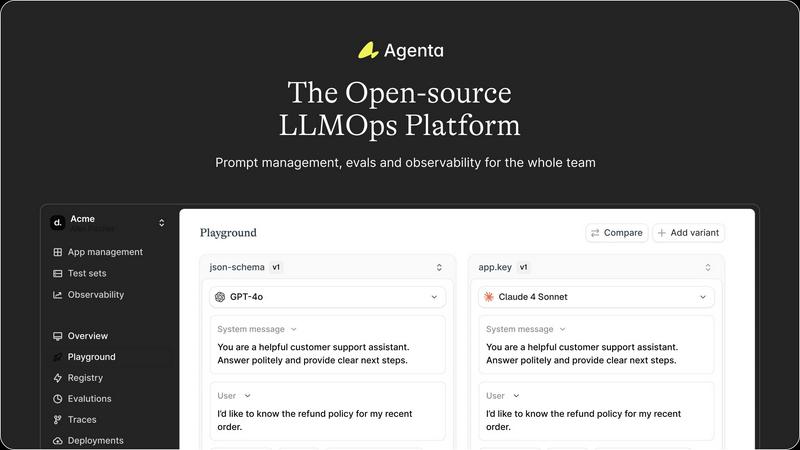
Visual Comparison
Agenta
OpenMark AI

Feature Comparison
Agenta
Unified Playground & Experimentation
Agenta provides a central, model-agnostic playground where your team can safely experiment with different prompts, parameters, and models from any provider side-by-side. This eliminates the need for scattered scripts and documents. Every iteration is automatically versioned, creating a complete history of your experiments so you can track what changed, why, and its impact. Found a problematic output in production? You can instantly save it as a test case and begin debugging right in the same interface.
Systematic Evaluation Framework
Move beyond "vibe testing" with Agenta's robust evaluation system. It allows you to create a systematic process to run experiments, track results, and validate every change before deployment. The platform supports any evaluator you need—LLM-as-a-judge, custom code, or built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into the evaluation workflow.
Production Observability & Debugging
When your LLM app is live, Agenta gives you clear visibility. It traces every user request, allowing you to pinpoint the exact step where failures occur. You and your team can annotate these traces to discuss issues or gather user feedback directly. With a single click, any problematic trace can be turned into a test case, closing the feedback loop. Live, online evaluations monitor performance continuously to detect regressions as they happen.
Collaborative Workflow for Whole Teams
Agenta breaks down silos by providing tools for every team member. It offers a safe, no-code UI for domain experts to edit and experiment with prompts. Product managers and experts can run evaluations and compare experiments directly from the UI, while developers work via a full-featured API. This parity between UI and API creates one central hub where everyone collaborates on experiments, versions, and debugging with real data.
OpenMark AI
Plain Language Task Description
Forget complex configuration files or scripting. OpenMark AI lets you start your benchmarking journey by simply describing the task you want to test in everyday language. Whether it's "extract dates and product names from customer emails" or "generate three creative taglines for a new coffee brand," you define the challenge naturally. The platform then helps you structure this into a validated benchmark, removing the technical barrier to rigorous testing and letting you focus on what matters: the task itself.
Multi-Model Comparison in One Session
The core of OpenMark's power is its ability to run your exact same prompt against dozens of leading models from providers like OpenAI, Anthropic, and Google simultaneously. You don't have to run separate tests, copy outputs between tabs, or manually calculate costs. In one unified session, you get side-by-side results, allowing for a direct, apples-to-apples comparison that reveals clear winners and surprising contenders for your specific use case.
Holistic Performance Metrics
OpenMark moves beyond simple accuracy. It provides a multi-dimensional report card for each model, including scored quality for your task, the actual cost per API request, response latency, and—importantly—stability metrics from repeat runs. This last feature shows you the variance in outputs, helping you identify models that are consistently good versus those that just got lucky once, which is critical for shipping reliable features.
Hosted Benchmarking with Credits
To streamline your exploration, OpenMark operates on a credit system, eliminating the need for you to obtain, configure, and manage separate API keys for every model provider you want to test. This hosted approach means you can start benchmarking immediately, with all the complexity handled in the background. It turns a multi-day setup process into a few clicks, making sophisticated model evaluation accessible to every developer and team.
Use Cases
Agenta
Streamlining Enterprise Chatbot Development
A financial services company is building a customer support chatbot. Their domain experts, compliance officers, and developers need to collaborate tightly. Using Agenta, they centralize prompt versions, run evaluations against regulatory compliance checklists and customer intent accuracy, and observe live interactions to quickly debug hallucinations or incorrect advice, ensuring a reliable and compliant final product.
Building and Tuning Complex AI Agents
A team is developing a multi-step research agent that searches the web, summarizes findings, and generates reports. Debugging is a nightmare when only the final output is wrong. With Agenta, they evaluate each intermediate step in the agent's reasoning chain, identify which tool call failed, and use the unified playground to iteratively fix the prompt for that specific step, dramatically improving the agent's reliability.
Managing Rapid Product Iteration with LLMs
A product team at a SaaS company uses LLMs to generate personalized email content. Marketing wants to test new tones, while engineers worry about stability. Agenta allows them to A/B test different prompt variations systematically, gather quantitative scores on engagement metrics and qualitative feedback from the sales team, and confidently deploy the winning variant with full version control and rollback capability.
Academic Research and Model Benchmarking
A research lab is comparing the performance of various open-source and proprietary LLMs on a new benchmark task. They use Agenta's model-agnostic playground to run the same prompt templates across all models, automate scoring using custom evaluation scripts, and maintain a rigorous, reproducible record of all experiments and results in one platform, streamlining their publication process.
OpenMark AI
Validating a Model Before Feature Ship
A product team is weeks away from launching a new AI-powered summarization feature. They've shortlisted three models but need concrete data to make the final, responsible choice. Using OpenMark, they benchmark all three on their actual user prompts, comparing not just summary quality but also cost efficiency and consistency. The evidence guides them to the optimal model, de-risking the launch and ensuring a high-quality user experience from day one.
Cost-Efficiency Analysis for Scaling
A startup with a successful AI chatbot needs to optimize its growing inference costs. They suspect a smaller, cheaper model might perform adequately for most user queries. They use OpenMark to run their common question types against both their current premium model and several cost-effective alternatives. The side-by-side comparison of quality scores versus real API costs reveals the perfect balance, potentially saving thousands without degrading service.
Building a Reliable RAG Pipeline
A developer is constructing a Retrieval-Augmented Generation system for a knowledge base. The choice of the final LLM for synthesis is critical. They use OpenMark to test various models with complex, multi-document queries, focusing heavily on the stability metric across repeat runs. This helps them select a model that provides factual, consistent answers every time, which is far more valuable than a model that occasionally produces brilliance but often hallucinates.
Agent Routing and Orchestration Decisions
An engineering team is designing an AI agent that must route subtasks to different specialized models. They need to know which model is best for classification, which excels at data extraction, and which is most cost-effective for simple formatting. OpenMark allows them to create a suite of micro-benchmarks for each task type, building a data-driven routing map that optimizes both performance and budget across their entire agentic workflow.
Overview
About Agenta
The journey of building with large language models is often a tale of chaos. Prompts are scattered across emails and Slack threads, experiments are launched on gut feeling, and debugging a failure in production feels like searching for a needle in a haystack. This is the unpredictable reality most AI teams face, where brilliant ideas get lost in siloed workflows and unreliable deployments. Agenta emerges as the guiding path through this wilderness. It is an open-source LLMOps platform designed to be the single source of truth for teams building reliable LLM applications. Agenta transforms the fragmented process into a structured, collaborative journey. It brings developers, product managers, and domain experts together into one unified workflow, allowing them to experiment with prompts, run systematic evaluations, and observe application behavior in production—all from a centralized platform. By replacing guesswork with evidence and silos with collaboration, Agenta empowers teams to iterate quickly, validate every change, and ship AI products you can truly trust.
About OpenMark AI
Imagine you're building a new AI feature. You've read the spec sheets, you've seen the leaderboards, but a nagging question remains: which model is truly the best for your specific task? Not for a generic benchmark, but for the exact prompt, the precise nuance, the unique data you need to process. This is the journey OpenMark AI was built for. It's a web application that transforms the complex, technical chore of LLM benchmarking into a straightforward, narrative-driven exploration. You simply describe your task in plain language—be it classification, translation, data extraction, or RAG—and OpenMark runs the same prompts against a vast catalog of over 100 models in a single session. The magic happens when you compare the results. You see not just a single, lucky output, but a comprehensive view of scored quality, real API cost per request, latency, and, crucially, stability across repeat runs. This reveals the variance, showing you which models are consistently reliable. Built for developers and product teams making critical pre-deployment decisions, OpenMark eliminates the hassle of configuring separate API keys for every provider. With a hosted, credit-based system, you can focus on finding the model that delivers the right quality for your budget, ensuring your AI feature is built on a foundation of evidence, not guesswork.
Frequently Asked Questions
Agenta FAQ
Is Agenta really open-source?
Yes, Agenta is a fully open-source platform. You can dive into the codebase on GitHub, self-host it on your own infrastructure, and contribute to its development. This ensures transparency, avoids vendor lock-in, and allows for deep customization to fit your specific LLMOps workflow and security requirements.
How does Agenta handle data privacy and security?
As an open-source platform, Agenta gives you full control over your data. You can deploy it within your private cloud or on-premise environment, ensuring that all prompts, evaluation data, and production traces never leave your network. This is crucial for enterprises in regulated industries like healthcare, finance, or legal services.
Can I use Agenta with my existing LLM framework?
Absolutely. Agenta is designed to be framework-agnostic. It seamlessly integrates with popular frameworks like LangChain and LlamaIndex, and it works with any model provider (OpenAI, Anthropic, Cohere, open-source models via Ollama, etc.). You can bring your existing applications and connect them to Agenta for the management, evaluation, and observability features.
Who on my team should use Agenta?
Agenta is built for the entire LLM application team. Developers use the API and SDK for integration, product managers and domain experts use the no-code UI to run evaluations and tweak prompts, and AI leads use the platform to oversee the entire experimentation lifecycle and production health. It bridges the gap between technical and non-technical stakeholders.
OpenMark AI FAQ
How does OpenMark ensure results are accurate and not cached?
OpenMark AI performs real, live API calls to each model provider during every benchmark run. The costs, latencies, and outputs you see are generated on-demand for your specific task. This guarantees you are comparing genuine, current performance data—the same experience you would have integrating the model directly—and not reviewing static, pre-computed marketing numbers that may not reflect real-world conditions.
What kind of tasks can I benchmark with OpenMark?
The platform is designed for a wide array of common and complex AI tasks. You can benchmark models for classification, translation, data extraction, question answering, research synthesis, image analysis, RAG (Retrieval-Augmented Generation) responses, agent routing logic, creative writing, and much more. If you can describe it in a prompt, you can likely build a benchmark for it.
Do I need my own API keys to use OpenMark?
No, one of the key conveniences of OpenMark is that it is a hosted benchmarking service. You operate using credits purchased or obtained through a plan. The platform manages all the underlying API connections to providers like OpenAI, Anthropic, and Google. This means you can start comparing models immediately without the administrative overhead of securing and configuring multiple keys.
Why is measuring stability or variance important?
A single test run can be misleading, as even the best models can occasionally produce a poor output, and weaker models can sometimes get lucky. By running your task multiple times and measuring variance, OpenMark shows you which models are consistently reliable. For shipping a production feature, consistency is often more critical than peak performance, as it builds user trust and ensures a predictable experience.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform, a specialized tool designed to streamline the complex journey of building and deploying large language model applications. It brings order to the often chaotic process by centralizing prompts, evaluations, and collaboration in one place. Teams often explore the landscape for alternatives driven by unique needs. This could be due to specific budget constraints, a requirement for different feature sets, or the need to integrate with an existing company tech stack. The search for the right tool is a common step in any team's evolution. When evaluating options, focus on what will best support your team's specific journey. Key considerations include the platform's ability to foster collaboration, its approach to testing and observability, and how well it integrates into your current workflow to reduce friction and accelerate development.
OpenMark AI Alternatives
Choosing the right LLM for your project is a critical, often frustrating, step. OpenMark AI is a developer tool designed to cut through that uncertainty by letting you benchmark over 100 models on your specific task, comparing real-world cost, speed, quality, and output stability in a single browser session. Developers and teams often explore alternatives for various reasons. Perhaps they need a solution that integrates directly into their CI/CD pipeline, requires a self-hosted option for data governance, or operates on a different pricing model. The needs of a solo builder differ from those of an enterprise team. When evaluating other tools in this space, focus on what matters for your workflow. Key considerations include whether the tool tests with live API calls or cached data, how it measures and scores output quality for your use case, its model catalog coverage, and how it handles the practicalities of API keys and cost transparency across providers.