ImageBind by Meta AI
About ImageBind by Meta AI
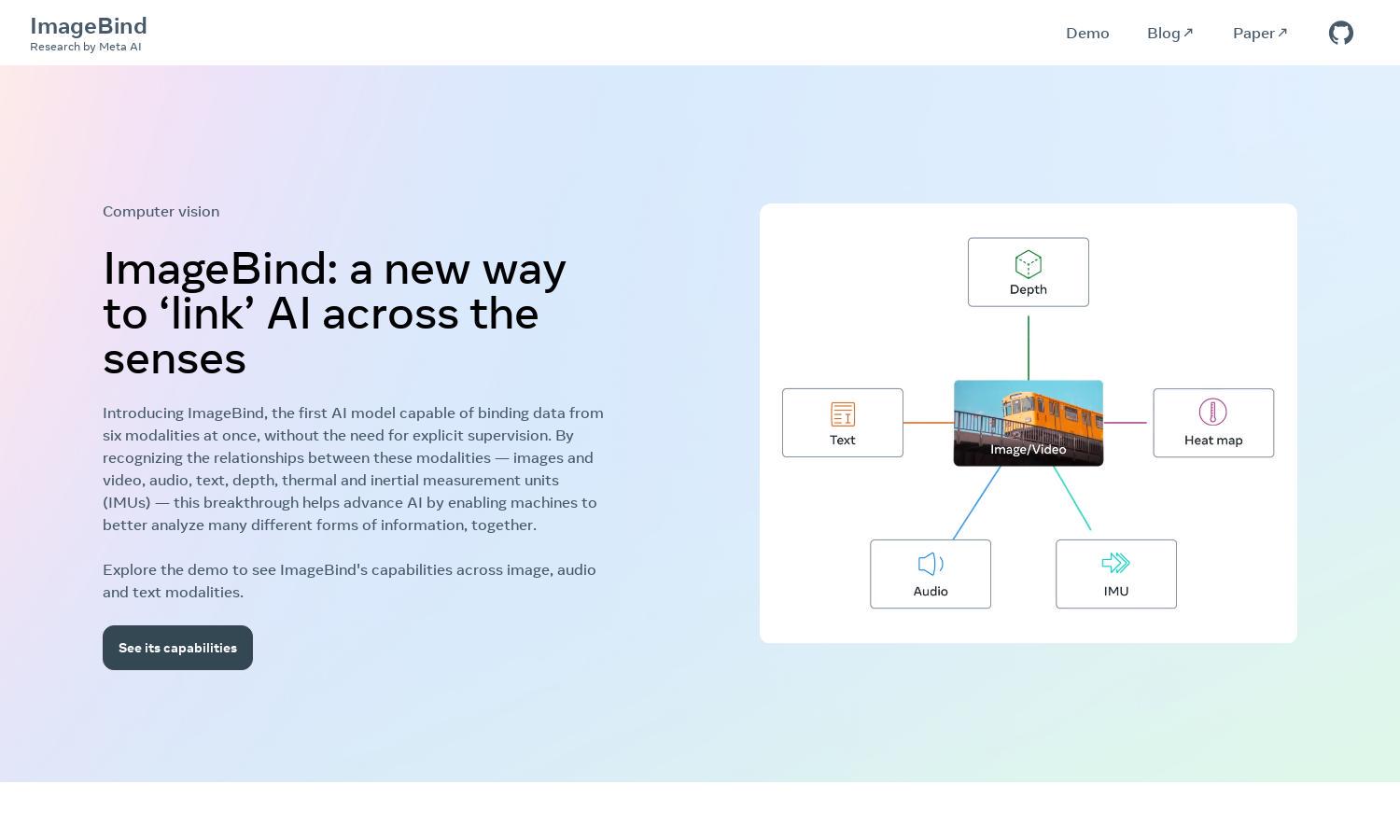
ImageBind by Meta AI revolutionizes data analysis through its unique multimodal capabilities. Designed for researchers and developers, it binds various sensory inputs like images, audio, and text into a unified embedding space. By eliminating the need for explicit supervision, ImageBind enables advanced AI applications, improving recognition and analysis.
ImageBind by Meta AI offers an open-source platform with flexible pricing plans designed for researchers and developers. Users can access tiered features, with special discounts available for early adopters. Upgrading unlocks enhanced capabilities, further optimizing multimodal analysis and improving user interaction within the platform.
ImageBind by Meta AI features an intuitive user interface that ensures a seamless browsing experience. Its layout is designed for easy navigation, highlighting unique features like multimodal search and cross-modal generation. By prioritizing user-friendliness, ImageBind effectively engages users, enhancing their experience in AI model exploration.
How ImageBind by Meta AI works
Users interact with ImageBind by Meta AI through an easy onboarding process, where they familiarize themselves with the platform's layout and capabilities. They can explore various features like cross-modal searching and multimodal arithmetic. By integrating inputs across six different modalities, ImageBind simplifies complex data analysis, making it accessible and efficient for all users.
Key Features for ImageBind by Meta AI
Multimodal Binding System
ImageBind's unique multimodal binding system allows users to integrate and analyze audio, images, text, and more simultaneously. This innovative feature enhances AI applications, enabling enriched data interpretation, cross-modal search functions, and efficient recognition, making ImageBind a pivotal tool for AI researchers and developers.
Zero-Shot Recognition
The zero-shot recognition feature of ImageBind enables remarkable performance across modalities without the need for extensive training on specific datasets. Users can leverage this capability to achieve superior recognition results, thus enhancing their machine learning models and expanding the range of tasks they can efficiently handle.
Cross-Modal Generation
ImageBind includes cross-modal generation capabilities that allow users to create new content by merging inputs from different sensory modalities. This unique feature empowers developers to innovate and enhance user experience, leading to more dynamic applications and further exploration of AI's potential in diverse fields.
You may also like: