Friendli Engine
About Friendli Engine
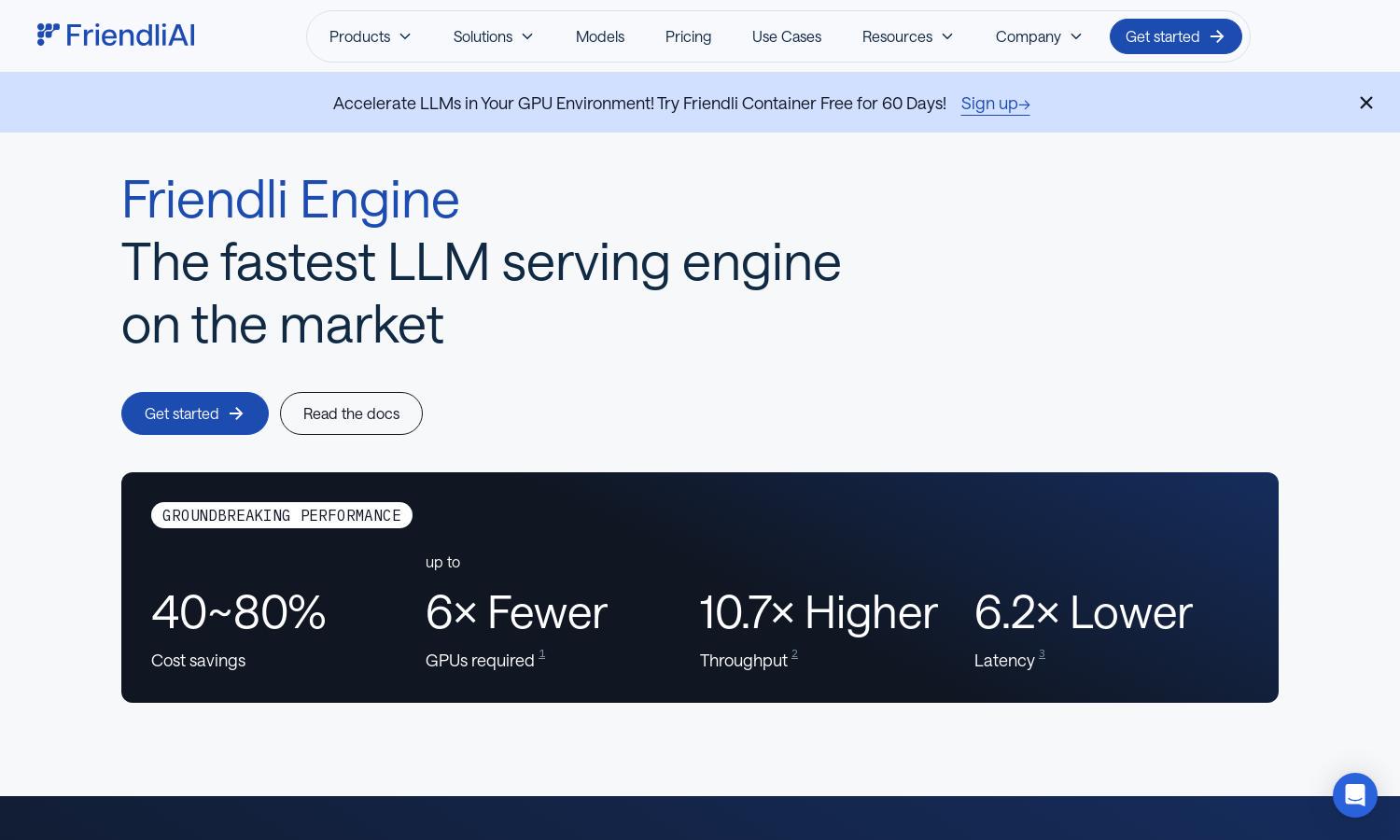
Friendli Engine is a powerful platform designed to optimize LLM inference for developers and businesses. It leverages innovative technologies like iteration batching and speculative decoding to facilitate rapid and cost-effective AI model deployment. Users benefit from improved throughput and reduced latency in generative AI applications.
Friendli Engine offers flexible pricing plans tailored for different needs. Users can choose from a free trial for basic access to comprehensive paid tiers that unlock advanced features. Upgrading provides enhanced performance and efficiency in LLM inference, making it ideal for businesses looking to optimize costs.
The user interface of Friendli Engine is designed for simplicity and efficiency. Its intuitive layout allows users to navigate effortlessly through options, ensuring a seamless experience. Unique features, such as dynamic model selection and real-time performance monitoring, enhance usability.
How Friendli Engine works
Users start by signing up for Friendli Engine and selecting the appropriate plan. Upon onboarding, they can easily upload their models and utilize tools like the Friendli Dedicated Endpoints for efficient LLM serving. The platform's streamlined dashboard guides users through performance monitoring and adjustments, ensuring enhanced inference speed and cost savings.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine features unique iteration batching technology, dramatically increasing LLM inference throughput. This innovation allows users to handle concurrent requests with remarkable efficiency, providing a significant advantage over traditional batching methods. The result is faster responses and improved user satisfaction.
Multi-LoRA Serving
One standout feature of Friendli Engine is its ability to support multiple LoRA models on a single GPU. This capability enhances the deployment of customized LLMs, making it easier for users to optimize their AI solutions efficiently while reducing hardware requirements.
Spectulative Decoding
Friendli Engine incorporates speculative decoding, an advanced technique that speeds up LLM inference by predicting future tokens based on current ones. This unique feature promotes faster response times while maintaining the accuracy of generated outputs, providing users with a competitive edge.








